
Here is the scenario: You started indexing data into Elasticsearch and you immediately want to start making some cool visualizations in Kibana. But then you happen to notice that your fields are of the text string data type instead of a long or float number type. So much for trying to create a line chart like you wanted!
What is this madness!? How do I fix this!?
The solution: Index Templates.
You need to create an index template for the index and define the data type for the field. That is how you fix the problem.
Whoa! Ok hold on a moment, wait just a minute there Joey D let's slow down. Why do I need to create an index template? Doesn't Elasticsearch automatically detect the field data type when I POST the document to the index?
It is true that the Elastic Stack is designed to allow you to get started very quickly with visualizing and indexing your data. One way it does this is by dynamic mapping. What this means is that you can POST a document directly to Elasticsearch and it will create the index (if it doesn't exist yet) and any new fields will auto-magically be detected and created with the closest data type that Elasticsearch thinks it should be – And that is the catch! In order to enforce the field data type you must define an index template for the index. Don't get me wrong about this feature though. Elasticsearch really does a fantastic job in automatically detecting what the field's data type should be. Sometimes Elasticsearch guesses wrong which is why index templates are a necessity, especially when planning to deploy to production and using the stack for the long term.
Index templates are how you define a schema mapping for an index. In it you define all of the field data types and so on. There are many different settings you can define in an index template (especially for ILM - another topic for another time). This is why creating an index template for your index is an important step to ensure data consistency.
So let's dive into some examples!
First, some simple environmental items:
- I'll be using the Insomnia REST client to POST documents to my Elastic Stack cluster.
- My test Elastic Stack cluster is running Elasticsearch and Kibana v7.5.2. Xpack security is not enabled.
- The index will be called "myindex".
- Each document I POST will have two numeric fields:
should-be-type-longandshould-be-type-float.
Let's create the index and send the first document...
POST http://mycluster:9200/myindex/_doc
{
"should-be-type-long": 100,
"should-be-type-float": 0.002251100009
}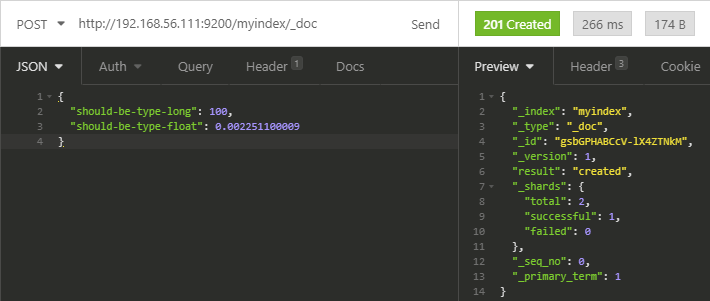
In the response from Elasticsearch we get HTTP 201 Created. We can see the result is created and there are no failures.
If we perform a search request against the index API for myindex, we can see the document we just created.
GET http://192.168.56.111:9200/myindex/_search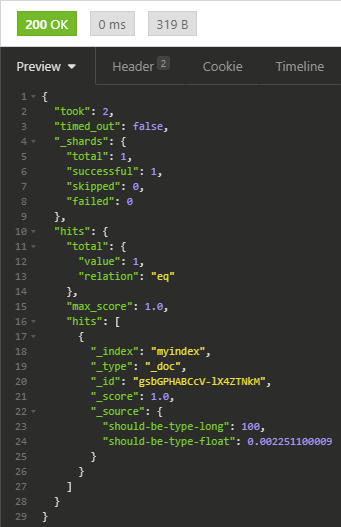
To verify the correct data type mapping was applied for each of the fields, we can use the Get mapping API.
GET http://192.168.56.111:9200/myindex/_mapping
The float field is the float type and the long field is the long type. This is exactly what we want.
But what if the value for should-be-type-long is "100.0" instead of a plain integer?
Let's start over. I deleted the index and sent a new POST with the new values...
DELETE http://192.168.56.111:9200/myindex
POST http://192.168.56.111:9200/myindex/_doc
{
"should-be-type-long": 100.0,
"should-be-type-float": 50.000000
}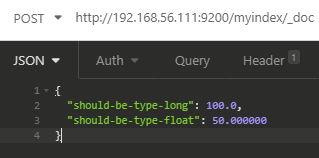
Querying the get mapping API shows that this field is now a float type.

In this example we observe that Elasticsearch properly assumed that the long field should be a float data type because of the decimal. If the value was "100" (a plain integer) then it would be a long type as shown in the first example.
What do you think will happen if I don't delete the index, but change the value for the should-be-type-long field from a floating point number back to a long?
This time, I will not start over and delete the index. I'm going to leave the existing index and mapping in place as-is.
Remember that in the previous example we see both fields are of the float data type.
I'm POSTed a new document to the same index, but changed the values to longs then use the search API to view the documents...
POST http://192.168.56.111:9200/myindex/_doc
{
"should-be-type-long": 123,
"should-be-type-float": 456
}
GET http://192.168.56.111:9200/myindex/_search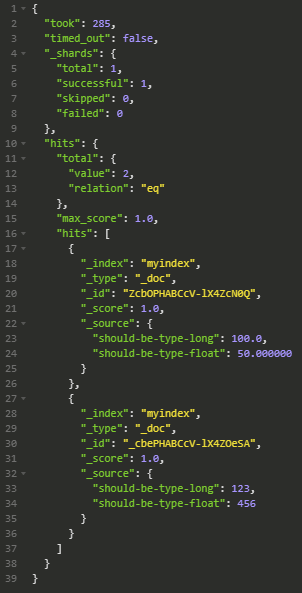
We can see both documents. The first with the values of 100.0 and 50.000000 and the 2nd document with 123 and 456 for the long and float fields respectively.
If you take a look at the mapping...
GET http://192.168.56.111:9200/myindex/_mapping
The field mappings did not change. Why not?
Because field mappings are applied only when the index is created.
Since I just added more documents to an existing index nothing happens to the field mappings because mappings are applied only at index creation. If you want to change a field's data type, you must create a new index or re-index the existing data into a new one that has new mappings. Details about why can be seen in this official Elastic blog post.
Important note: If you change field mappings in an index template, and you use Kibana, remember to refresh the index patterns in Kibana.
Some very interesting issues can happen in environments where index templates do not exist. One of the most obvious is that in Kibana, it would appear that string fields are duplicated with the duplicate having .keyword appended at the end of the field's name. For example, looking at the index pattern in Kibana we might see something like this...
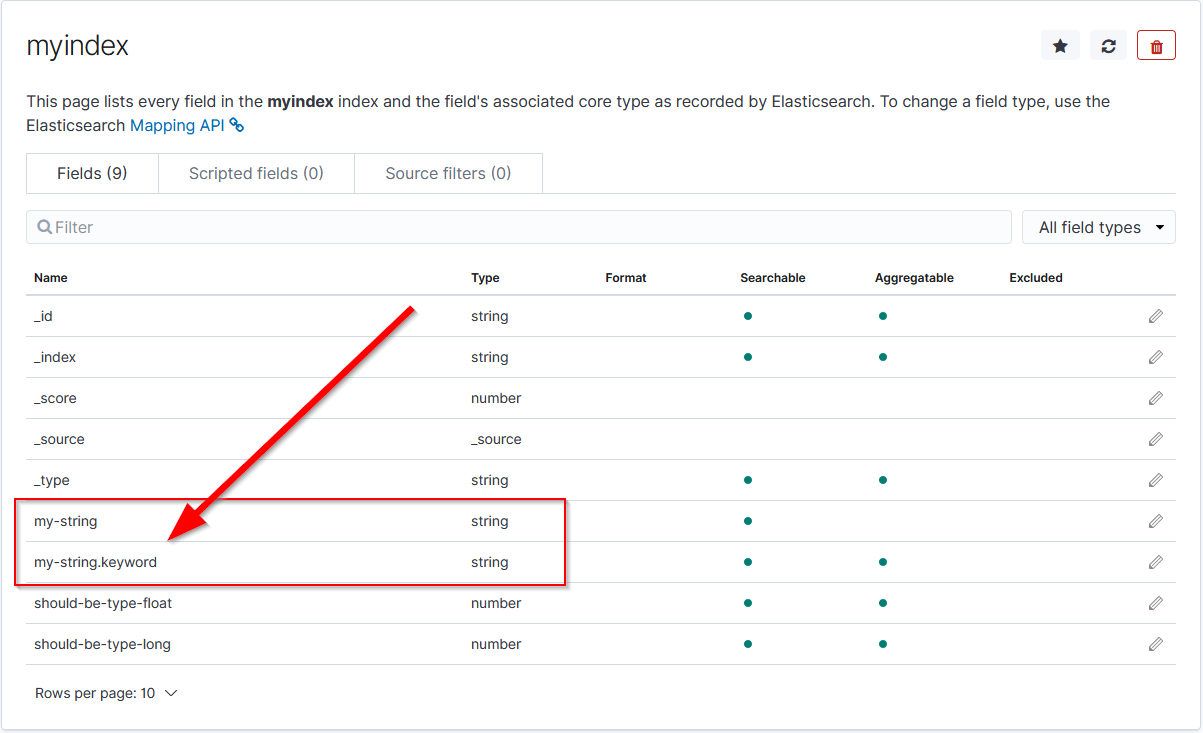
There is an excellent short post about this on Stack Overflow. The SO post explains what is going on technically so I'll let you read that (see the first answer) if you are interested.
The TL;DR on this is that both fields are correct from an Elasticsearch point of view. However only keyword string data types are aggregatable in Kibana while the text string data type is not. The good news is that both are searchable in Elasticsearch queries. But the bad news is that in Kibana a field must be aggregatable in order to use it in visualizations. All non-aggregatable fields are of the text string data type.
Without an index template available to let Elasticsearch know how to handle the string field type it is processing, Elasticsearch's dynamic mapping feature will auto-magically makes both string types for each document in the index. This can be bad depending on the size of the data set as this will duplicate the storage required, in both memory and disk volume, to store the field data in the index.
In another example, I've seen a new index created where a field was supposed to be a float data type, but the first document's field in the new index had a value of "0" (with no decimal) so the dynamic mapping created the field as a long. All future documents sent to Elasticsearch had field values that really were floats (i.e. 0.593.... or 0.900241... and so on) but because the initial index was created with the mapping of long, they couldn't create any meaningful Kibana dashboards. It wasn't until I helped re-index the data set with an index template that the float numbers worked as expected and we could build dashboards.
So... do you want to improve both indexing, search speeds, or Kibana dashboards for an index? Make sure the index has an index template with field mappings.
Do you want to reduce the memory footprint of an index? Make sure the index has an index template with field mappings.
Do you want to ensure field data type consistency in an index or through common index patterns (such as timeseries indices like metricbeat-yyyy.MM.dd)? Index template... field mappings...
Do you want/need to reduce the shard count of an index? Index template... field mappings...
Do you want/need to reduce the disk volume footprint of an index? Index template... field mappings... You get the point.
I hope all of this information helps you with your projects and helps you understand the why index templates in Elasticsearch are an import peice of the data modeling puzzle when architecting, planning, and improving performance of your Elastic Stack clusters.
-Joey D